Diving into Email Headers
I’ve been meaning to revisit something I spend a good deal of time on in a past life. Email headers can be a valuable source of intelligence when combating anything from basic spam all the way to targeted phishing campaigns. In my experience, even sophisticated attackers do not make much of an attempt to vary items within headers.
What we want to do is increase the cost for the attackers. Lets try to take away this shortcut.
I’ve started experimenting with bringing mail headers into Splunk with the help of this extremely useful script: https://github.com/Newsman/MailToJson I’d like to thank them for open sourcing it, as it saved me quite a bit of time. I wrote a very simple Splunk TA to bring this data in correctly:
Props.conf:
[mail_json]
# https://github.com/Newsman/MailToJson
# Index time
LINE_BREAKER = ([\r\n]+)\{
SHOULD_LINEMERGE = false
TIME_PREFIX = \"datetime\":\s+\"
MAX_TIMESTAMP_LOOKAHEAD = 35
TRUNCATE = 999999
TIME_FORMAT = %Y-%m-%d %T
#"datetime": "2010-05-07 10:50:21"
# I'm working with Old data, so it's okay to be old.
MAX_DAYS_AGO = 10951
# Search time
KV_MODE = json
REPORT-mail_src_ip = mail_src_ip
REPORT-mail_spf_extracts = mail_spf_extracts
REPORT-mail_urls = mail_url_extract
EVAL-action = "allowed"
EVAL-vendor_product = "MailToJson"
FIELDALIAS-cim_for_mail_json = headers.message-id AS message_id, attachments{}. filename AS file_name, from{}.email AS src_user, headers.to AS recipient, reply-to{}. email AS return_addr
Transforms.conf:
[mail_src_ip]
SOURCE_KEY = headers.received{}
REGEX = [\s\(\[](?<src>(?<src_ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}))[\s\)\]]
MV_ADD = true
[mail_spf_extracts]
SOURCE_KEY = headers.received-spf
REGEX = (?<spf_action>\w+)\s\((?<spf_reason>[^\)]+)\)\s
[mail_url_extract]
SOURCE_KEY = parts{}.content
# http://stackoverflow.com/questions/6038061/regular-expression-to-find-urls-within-a- string
# There are some FPs with this regex, but it's a good start.
REGEX = (?<url>(?i)(?:(?:https?|ftp|file):\/\/|www\.|ftp\.)(?:\([-A-Z0-9+&@#\/ %=~_|$?!:,.]*\)|[-A-Z0-9+&@#\/%=~_|$?!:,.])*(?:\([-A-Z0-9+&@#\/%=~_|$?!:,.]*\)|[A-Z0-9+ &@#\/%=~_|$]))
MV_ADD = true
As you can see, I didn’t spend much time on Common Information Model compliance, but the bones are there. As the data comes out of the script as JSON, it’s extremely easy to work with. Here’s an example of the data in Splunk:

Now let’s get into some analysis on the headers. There are some really quick wins avaliable right away with SPF:
index=mail NOT (spf_action=pass OR spf_action=neutral) spf_action=* | stats values(subject) by src_ip
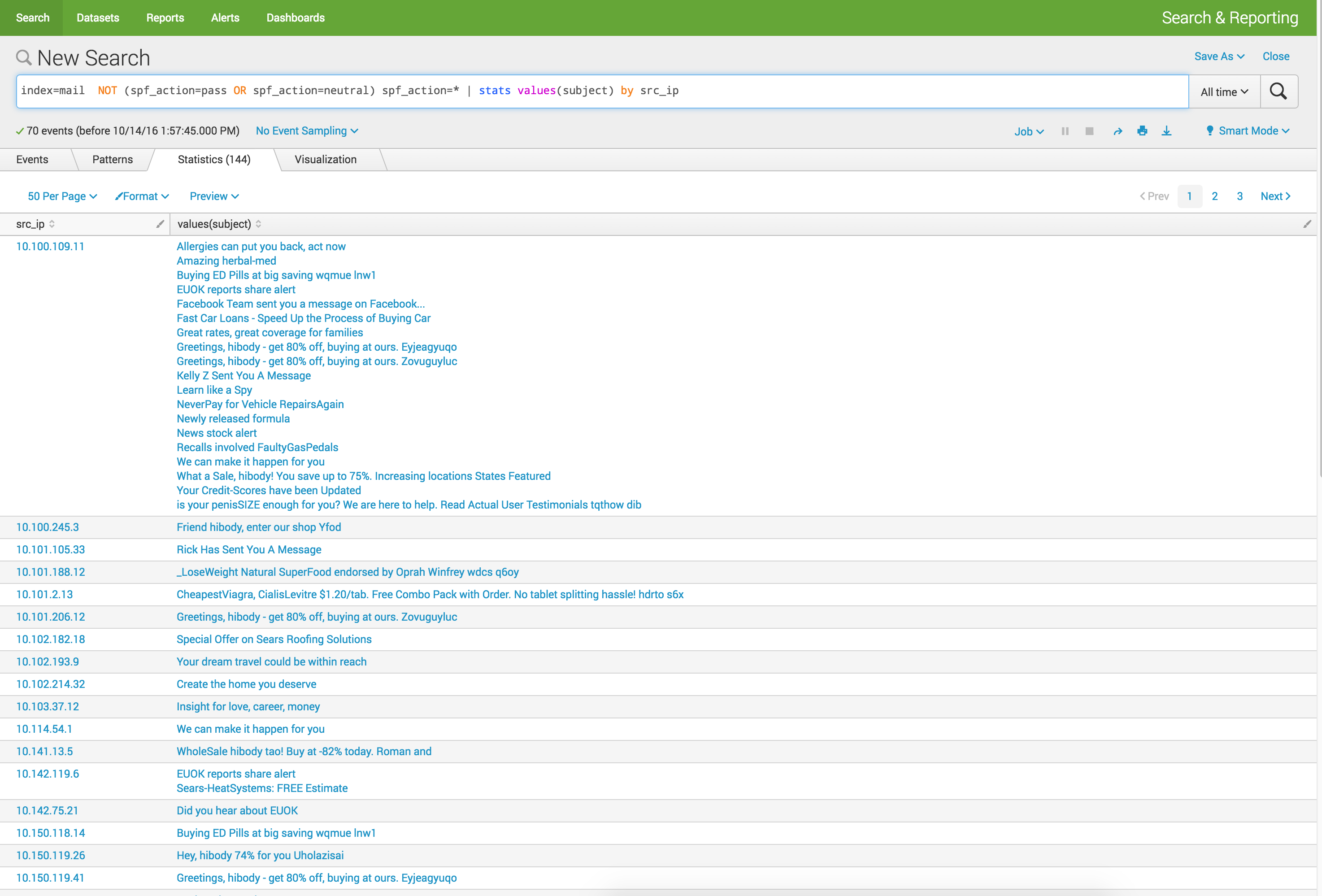
A quick look shows anything that has a SPF action that is “negative” looks to be spam. Within the data set I have at my disposable, simply having a DKIM signature is a positive sign. Nothing too surprising here, lets move on.
Since this script gives us the body of the message, we can attempt to pull URLs out of it. Once we’ve done that, we can sic the URL Toolbox at it! A simple search with the url toolbox nets us a few additional fields we can play with.
index=mail | `ut_parse_simple(url)`
With this, we can go back to our Spam from earlier and look at the URLs included in the Spam.
index=mail NOT (spf_action=pass OR spf_action=neutral) spf_action=* | `ut_parse_simple(url)` | stats values(ut_netloc) by src_user
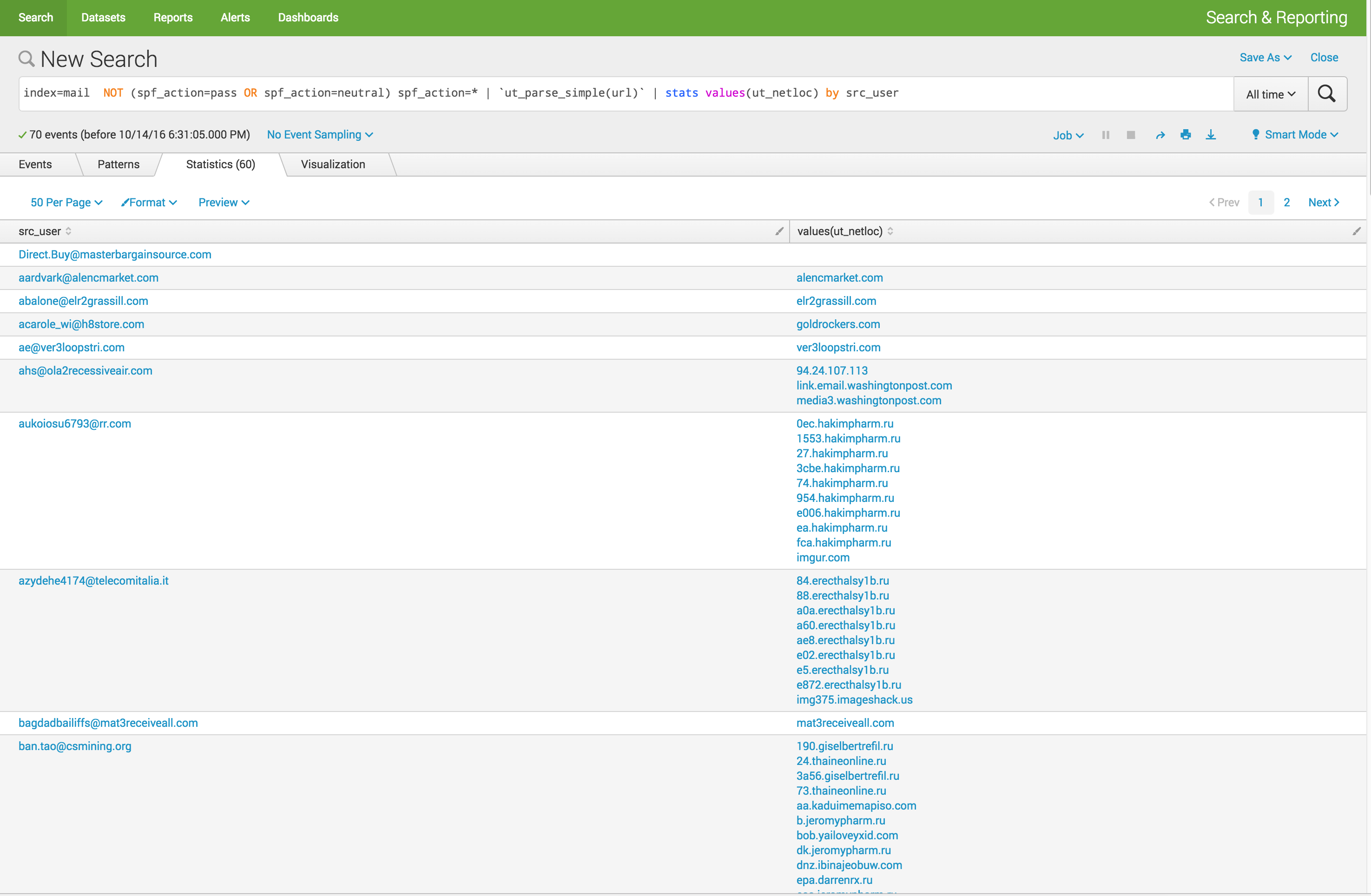
Right away, some senders stick out. It also appears we have multiple destinations for our more suspicious users. Lets dig further.
index=mail NOT (spf_action=pass OR spf_action=neutral) spf_action=* | `ut_parse_simple(url)` | stats dc(ut_netloc) AS unique_dest_domain by src_user | sort - unique_dest_domain | head 10
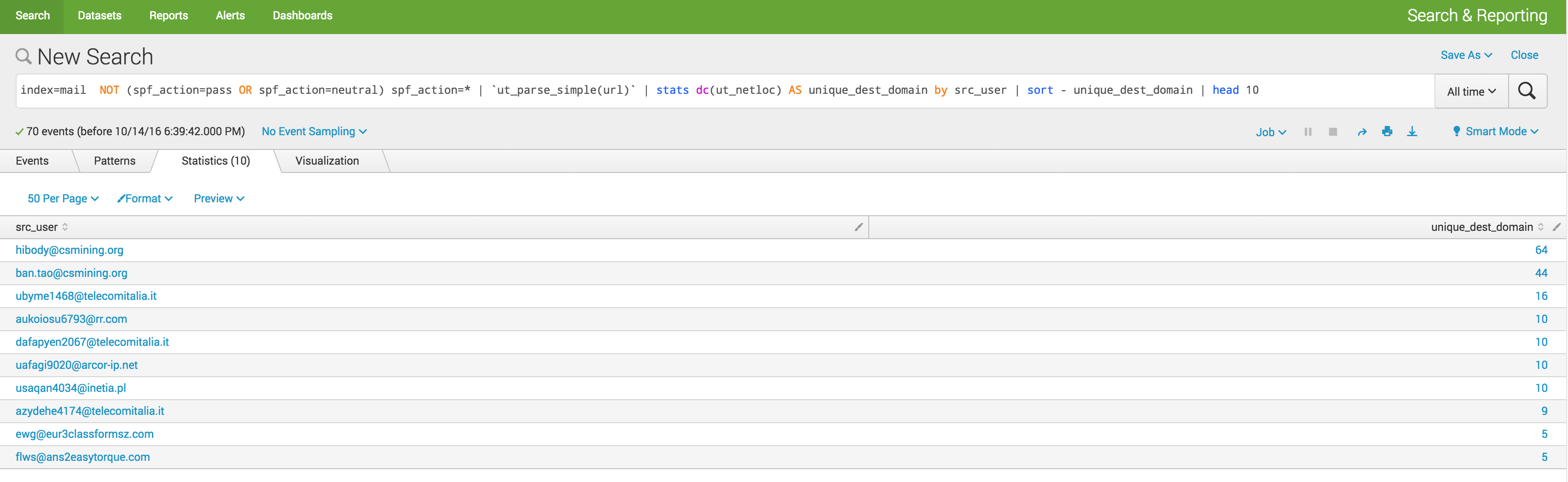 Looking at the URLs from these top 10, there are a lot of call outs to nasty looking domains. While there may be some bias in the data i’m using, all of the top 10 in this list, all 10 in this list were SPAM not HAM.
Looking at the URLs from these top 10, there are a lot of call outs to nasty looking domains. While there may be some bias in the data i’m using, all of the top 10 in this list, all 10 in this list were SPAM not HAM.
I think another interesting use case for this data in search is applying threat intelligence data to it. Lets take a look at what a few examples may look like:
index=mail [|inputlookup badIPs.csv | fields ip | rename ip AS src_ip | format] |stats values(headers.from) AS sender, values(headers.to) AS recipient by src_ip
This search will take a lookup bad IPs and search them against all IPs found in the received headers. You get the idea, you could apply this technique to any aspect of the headers. What’s more interesting is making the data Common Information Model compliant and having ES do the work.
Aside from the one off use cases above, I believe these are a couple of options for how to integrate this into an analyst’s routine:
-
All inbound mail headers get logged into Splunk This will allow threat research on all aspects of a message, finding patterns within a wider set of data beyond the typical to, from, subject and connecting host data set. You’ll be able to perform threat list IP / Domain matches on the entire recieved portion of the message.
- Advantages:
- Full coverage of all mail
-
Disadvantages:
-
How do you actually get this data? Build your own MTA? Unlikely. Off the wire? I hope it’s not encrypted.
-
Data volume
-
Potential PII concerns
-
- Advantages:
-
A tool for analysts when dealing with user reported “suspicious” messages This seems to be the more attractive option. It solves the data volume issue and collection issue. Setup a monitored mailbox (suspicious@company.tld) and modify the script to monitor that mail box. Ideally users would forward their messages as attachments to preserve all data (headers, attachments, body). You then can use Splunk to alert on new suspicious messages and parse their headers. An analyst simply looks at the results in Splunk, instead of looking at the message manually.
-
Advantages:
-
Low volume
-
Improved analyst work flow
-
Empowers the user to report suspicious activity
-
-
Disadvantages:
-
Relies on the user
-
Not the full set of email data
-
-
Lastly, if anyone has a data source they’d be willing to share that contains phishing, spam or malicious emails then I’d be very interested (particularly for phishing and malicious emails).